¿Que es un árbol de decisión?
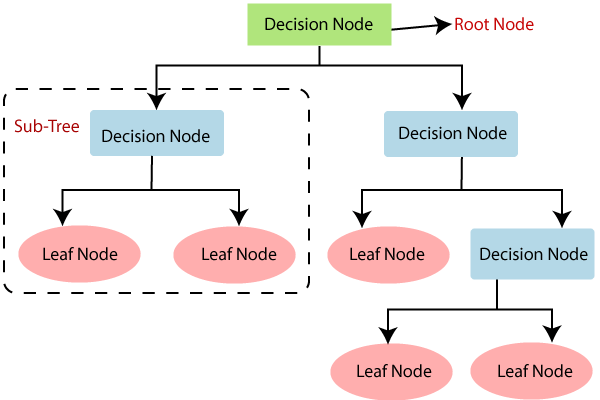
Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial. Dada una base de datos se construye un árbol de decisión para poder llegar a la conclusión deseada. Es una herramienta de apoyo para la toma de decisiones.
¿Que es un método de ensamblaje?
Los métodos de ensamblaje son métodos que combinan varios algoritmos de aprendizaje automático para obtener un mejor rendimiento predictivo que un solo algoritmo de aprendizaje automático. Los métodos de ensamblaje funcionan mejor cuando los predictores individuales están correlacionados entre sí.
Muestras con reemplazo
En estadística, el muestreo con reemplazo es un método de muestreo en el que, para cada extracción, el elemento elegido se devuelve a la población y se mezcla con el resto de elementos. El muestreo con reemplazo es un método de muestreo no exhaustivo.
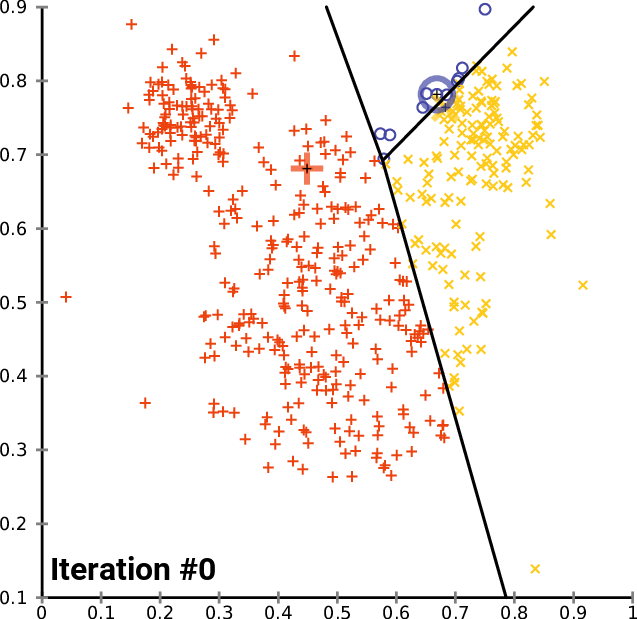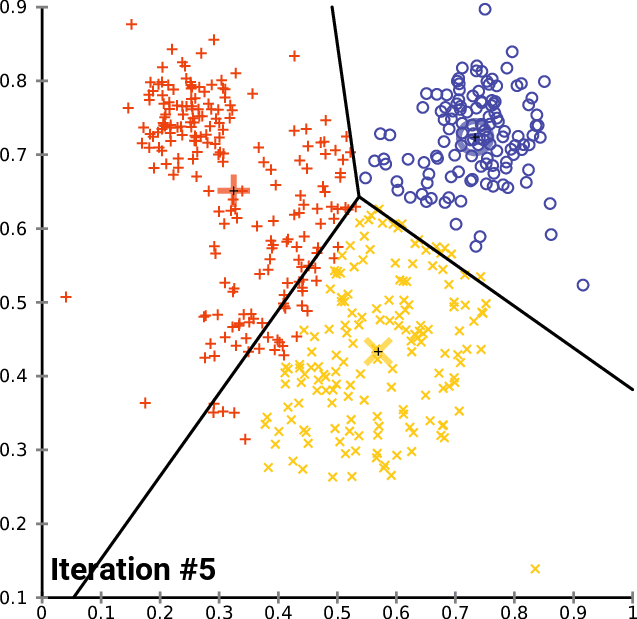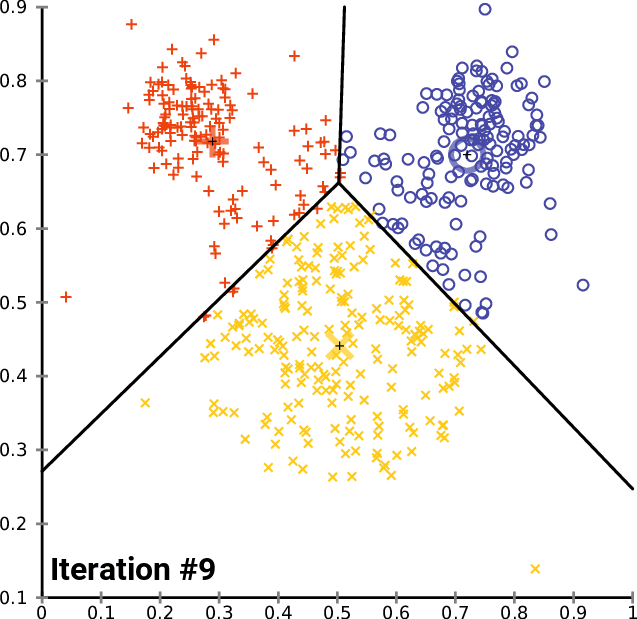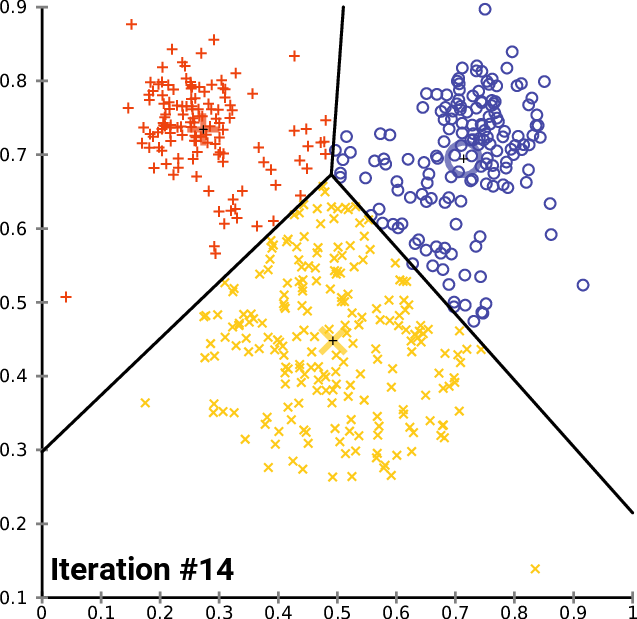
En arboles de decisión se utiliza el muestreo con reemplazo para generar los árboles de decisión que se utilizaran para el ensamblaje, es decir, se generan varios árboles de decisión con muestras de la base de datos original, y se combinan para generar un modelo más robusto.
Random Forest
Random Forest es un método de ensamblaje que combina varios árboles de decisión, cada uno de los cuales se genera con una muestra de la base de datos original, y se combinan para generar un modelo más robusto. esteme metodo usa el muestreo con reemplazo para generar los árboles de decisión.
Tenemos un datos de entrenamiento de tamaño
- para b = 1 hasta B: Utilizamos el muestreo con reemplazo para generar una muestra de tamaño de la base de datos original. Entrenamos un árbol de decisión con la muestra generada.
- Se obtiene el modelo final combinando los árboles de decisión generados.
Cuando usamos este algorithmo, muchas veces tenemos la misma división en el nodo raíz, por lo que podemos modificar un poco el algorithmo para que esto no suceda, y así obtener un mejor modelo.
Elección de características aleatorias
En cada nodo, se elige un subconjunto aleatorio de características de todo el conjunto de características. si es el número total de características, se recomienda para la regresión y para la clasificación, debe de tener en cuenta que esto es recomendado para un gran número de características
XGBoost ( ExTreme Gradient Boosting)
XGBoost es un método de ensamblaje que combina varios árboles de decisión, cada uno de los cuales se genera con una muestra de la base de datos original, y se combinan para generar un modelo más robusto. este metodo usa el muestreo con reemplazo para generar los árboles de decisión.
Pero a diferencia de Random Forest, XGBoost utiliza un algorithmo de optimización para generar los árboles de decisión, En vez de utilizar el muestreo con reemplazo para generar los árboles de decisión con una probabilidad uniforme , XGBoost utiliza un algorithmo de optimización para generar los árboles de decisión con una probabilidad que depende de la pérdida de la iteración anterior.
Donde:
- es la pérdida de la iteración
- es un parámetro de regularización
La idea de esto es que el algorithmo de optimización se enfoque en las muestras que tienen una pérdida mayor, y así generar un mejor modelo.
Ventajas de XGBoost
- Implementaciónes open source en varios lenguajes de programación
- Rapidez en el entrenamiento
- Buena elección de divisiónes criticas por defecto y criterio para cuando parar de dividir
- Regularización para evitar el sobreajuste
Implementación en Python
Para la implementación en Python, se utilizara la librería XGBoost, la cual se puede instalar con el comando:
from xgboost import XGBClassifier
model = XGBClassifier() # XGBRegressor para regresión
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
Cuando usar Arboles de decisión y métodos de ensamblaje
- Trabajan bien con datos tabulares (estructurados)
- No se recomienda para datos no estructurados (imágenes, texto, audio, etc)
- Es muy rápido en entrenamiento y predicción
- Pequeños arboles de decisión son fáciles de interpretar (visualizar)
Cuando usar neural networks
- Trabaja bien con todo tipo de datos tabulares "estructurados" y "no estructurados"
- Puede ser lento en entrenamiento y predicción
- Trabaja con transfer learning
- Cuando trabajamos con multiples modelos juntos, puede ser mas sencillo encadenarlos con una red neuronal