
¿Que es clustering?
Clustering es un método de aprendizaje no supervisado, que consiste en agrupar un conjunto de objetos de tal manera que los objetos del mismo grupo (o cluster) sean más similares (en algún sentido o en algún aspecto) entre sí que los de otros grupos.
k-means
k-means es un algoritmo de clustering que consiste en agrupar un conjunto de objetos de tal manera que los objetos del mismo grupo (o cluster) sean más similares (en algún sentido o en algún aspecto) entre sí que los de otros grupos.
Algoritmo de k-means
- Inicializar los centroides de los clusters aleatoriamente (k puntos):
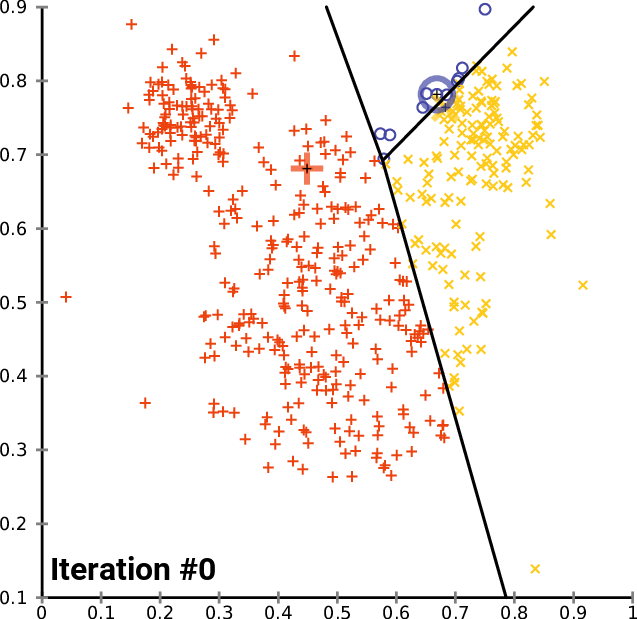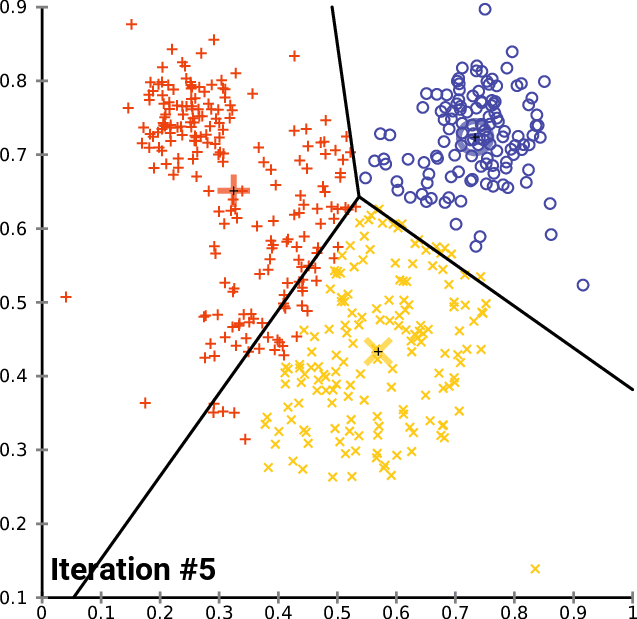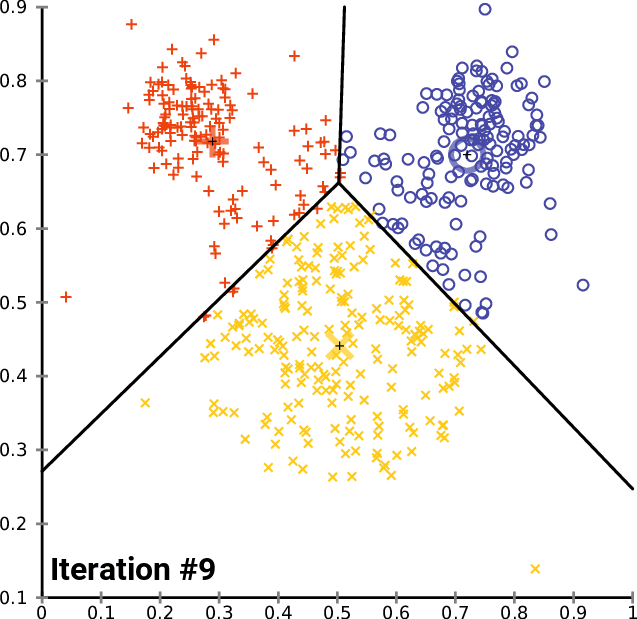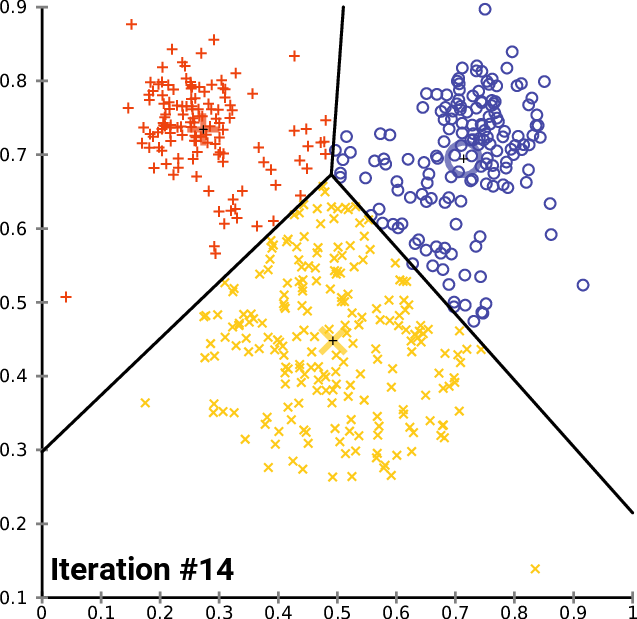
k-means optimización objetivo
- = índice del cluster (1, 2, ..., k) al que se asigna el ejemplo
- = vector de parámetros del centroide del cluster
- = vector de parámetros del centroide del cluster al que se asigna el ejemplo
Función de costo
Objetivo: Encontrar que minimicen .
Inicializando k-means
- Seleccionar aleatoriamente ejemplos de entrenamiento que servirán como los centroides iniciales: .
Elección del número de clusters
¿Cual es el número de clusters óptimo?
Para elegir el número de clusters óptimo se puede utilizar los siguientes 2 métodos:
- Método del codo: el metodo del codo consiste en graficar el valor de la función de costo en función del número de clusters . El número de clusters óptimo será el valor de en el que la función de costo se "quiebre" o tenga un cambio de pendiente más pronunciado.
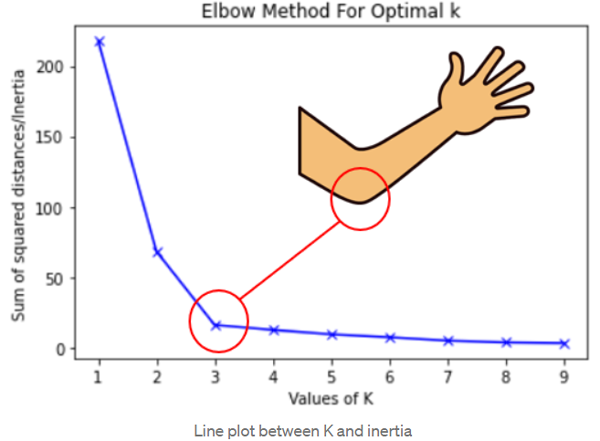
No es una buena métrica para elegir el número de clusters óptimo, ya que no siempre se puede identificar un cambio de pendiente claro en la gráfica, no hay un codo claro.
la elección del número de clusters es subjetiva, depende de la aplicación y del contexto.