pivot
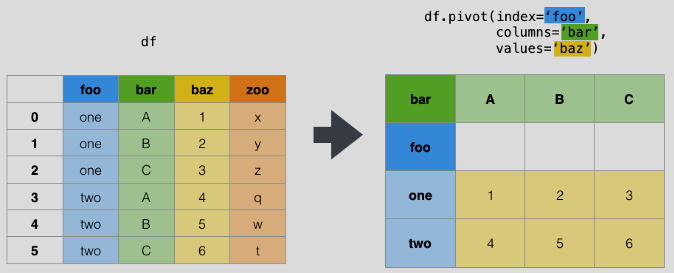
df.pivot(index='foo', columns='bar', values='baz')
df.pivot_table(index='foo', columns='bar', values='baz', aggfunc='sum')
melt
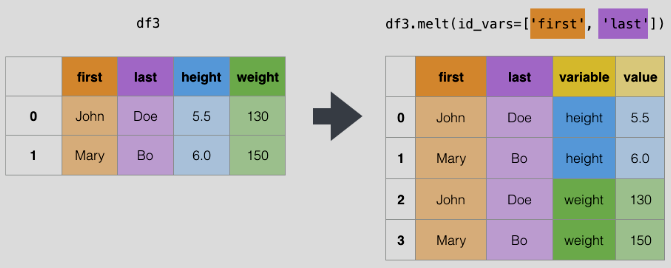
df3.melt(id_vars=['first', 'last'], var_name='variable',
value_name='value')
df3.melt(id_vars=['first', 'last'], var_name='variable',
value_name='value', value_vars=['height', 'weight'])
Wide to long

pd.wide_to_long(df, stubnames=['age', 'weight'], i=['name'],
j='year')
# format age_2019
pd.wide_to_long(df, stubnames=['age', 'weight'], i=['name'],
j='year', sep='_', suffix='\w+')
